2015-03-09 04:48:27 +00:00
|
|
|
grab-site
|
|
|
|
|
===
|
|
|
|
|
|
2015-12-12 17:58:52 +00:00
|
|
|
[![Build status][travis-image]][travis-url]
|
|
|
|
|
|
2015-07-29 08:55:06 +00:00
|
|
|
grab-site is an easy preconfigured web crawler designed for backing up websites.
|
|
|
|
|
Give grab-site a URL and it will recursively crawl the site and write
|
2015-07-18 09:54:07 +00:00
|
|
|
[WARC files](http://www.archiveteam.org/index.php?title=The_WARC_Ecosystem).
|
2018-10-04 13:40:28 +00:00
|
|
|
Internally, grab-site uses [a fork](https://github.com/ludios/wpull) of
|
|
|
|
|
[wpull](https://github.com/chfoo/wpull) for crawling.
|
2015-03-09 04:48:27 +00:00
|
|
|
|
2015-07-18 09:54:07 +00:00
|
|
|
grab-site gives you
|
|
|
|
|
|
2015-07-18 11:25:00 +00:00
|
|
|
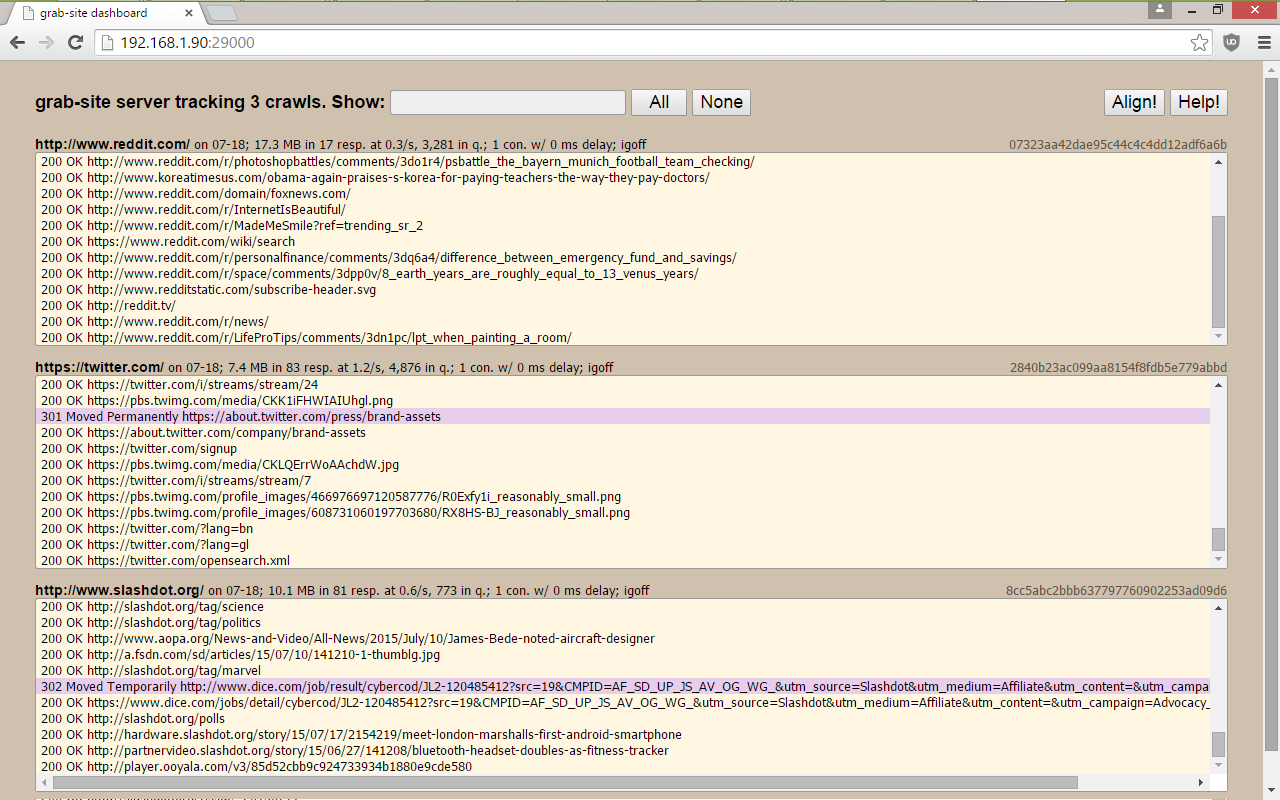
* a dashboard with all of your crawls, showing which URLs are being
|
2015-07-18 09:54:07 +00:00
|
|
|
grabbed, how many URLs are left in the queue, and more.
|
|
|
|
|
|
|
|
|
|
* the ability to add ignore patterns when the crawl is already running.
|
|
|
|
|
This allows you to skip the crawling of junk URLs that would
|
|
|
|
|
otherwise prevent your crawl from ever finishing. See below.
|
2015-03-09 04:48:27 +00:00
|
|
|
|
2015-07-29 08:55:06 +00:00
|
|
|
* an extensively tested default ignore set ([global](https://github.com/ludios/grab-site/blob/master/libgrabsite/ignore_sets/global))
|
2015-08-21 05:20:26 +00:00
|
|
|
as well as additional (optional) ignore sets for forums, reddit, etc.
|
2015-07-18 09:58:17 +00:00
|
|
|
|
2015-07-18 10:02:10 +00:00
|
|
|
* duplicate page detection: links are not followed on pages whose
|
2015-07-18 10:01:25 +00:00
|
|
|
content duplicates an already-seen page.
|
|
|
|
|
|
2015-07-27 07:59:57 +00:00
|
|
|
The URL queue is kept on disk instead of in memory. If you're really lucky,
|
|
|
|
|
grab-site will manage to crawl a site with ~10M pages.
|
|
|
|
|
|
2015-07-18 11:22:28 +00:00
|
|
|
|
2015-07-18 11:19:07 +00:00
|
|
|
|
2017-11-19 04:11:57 +00:00
|
|
|
Note: if you have any problems whatsoever installing or getting grab-site to run,
|
|
|
|
|
please [file an issue](https://github.com/ludios/grab-site/issues) - thank you!
|
|
|
|
|
|
2015-10-12 08:24:26 +00:00
|
|
|
**Contents**
|
|
|
|
|
|
2018-05-19 19:31:19 +00:00
|
|
|
- [Install on Ubuntu 18.04, Debian 9 (stretch), Debian 10 (buster)](#install-on-ubuntu-1804-debian-9-stretch-debian-10-buster)
|
2017-12-07 02:36:14 +00:00
|
|
|
- [Install on Ubuntu 14.04, 16.04, Debian 8 (jessie)](#install-on-ubuntu-1404-1604-debian-8-jessie)
|
2018-10-04 15:01:36 +00:00
|
|
|
- [Install on a non-Debian/Ubuntu distribution lacking Python 3.7.x](#install-on-a-non-debianubuntu-distribution-lacking-python-34x)
|
2017-10-24 17:42:33 +00:00
|
|
|
- [Install on macOS](#install-on-macos)
|
2017-10-24 16:43:10 +00:00
|
|
|
- [Install on Windows 10 (experimental)](#install-on-windows-10-experimental)
|
2015-10-12 08:24:26 +00:00
|
|
|
- [Upgrade an existing install](#upgrade-an-existing-install)
|
|
|
|
|
- [Usage](#usage)
|
2015-12-06 06:00:04 +00:00
|
|
|
- [`grab-site` options, ordered by importance](#grab-site-options-ordered-by-importance)
|
2016-02-17 21:49:35 +00:00
|
|
|
- [Warnings](#warnings)
|
2015-12-11 08:39:36 +00:00
|
|
|
- [Tips for specific websites](#tips-for-specific-websites)
|
2015-10-12 08:24:26 +00:00
|
|
|
- [Changing ignores during the crawl](#changing-ignores-during-the-crawl)
|
|
|
|
|
- [Inspecting the URL queue](#inspecting-the-url-queue)
|
2018-08-28 01:30:35 +00:00
|
|
|
- [Preventing a crawl from queuing any more URLs](#preventing-a-crawl-from-queuing-any-more-urls)
|
2015-10-12 08:24:26 +00:00
|
|
|
- [Stopping a crawl](#stopping-a-crawl)
|
|
|
|
|
- [Advanced `gs-server` options](#advanced-gs-server-options)
|
|
|
|
|
- [Viewing the content in your WARC archives](#viewing-the-content-in-your-warc-archives)
|
|
|
|
|
- [Inspecting WARC files in the terminal](#inspecting-warc-files-in-the-terminal)
|
2016-02-08 20:15:51 +00:00
|
|
|
- [Automatically pausing grab-site processes when free disk is low](#automatically-pausing-grab-site-processes-when-free-disk-is-low)
|
2015-10-12 08:24:26 +00:00
|
|
|
- [Thanks](#thanks)
|
|
|
|
|
- [Help](#help)
|
|
|
|
|
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
2018-05-19 19:31:19 +00:00
|
|
|
Install on Ubuntu 18.04, Debian 9 (stretch), Debian 10 (buster)
|
2015-03-09 04:48:27 +00:00
|
|
|
---
|
2017-12-07 02:36:14 +00:00
|
|
|
On Debian, use `su` to become root if `sudo` is not configured to give you access.
|
|
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2015-12-17 15:17:40 +00:00
|
|
|
sudo apt-get update
|
2018-10-04 14:09:27 +00:00
|
|
|
sudo apt-get install --no-install-recommends git build-essential pkg-config libssl1.0-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev libxml2-dev libxslt1-dev libre2-dev
|
2017-12-07 02:26:12 +00:00
|
|
|
wget https://raw.githubusercontent.com/pyenv/pyenv-installer/master/bin/pyenv-installer
|
|
|
|
|
chmod +x pyenv-installer
|
|
|
|
|
./pyenv-installer
|
2018-10-04 15:01:36 +00:00
|
|
|
~/.pyenv/bin/pyenv install 3.7.0
|
|
|
|
|
~/.pyenv/versions/3.7.0/bin/python -m venv ~/gs-venv
|
2018-10-05 08:12:43 +00:00
|
|
|
~/gs-venv/bin/pip install --process-dependency-links --no-binary --upgrade git+https://github.com/ludios/grab-site
|
2015-02-05 04:25:49 +00:00
|
|
|
```
|
|
|
|
|
|
2017-11-22 17:24:47 +00:00
|
|
|
Add this to your `~/.bashrc` or `~/.zshrc` and then restart your shell (e.g. by opening a new terminal tab/window):
|
2015-07-20 07:25:06 +00:00
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2017-10-24 17:24:27 +00:00
|
|
|
PATH="$PATH:$HOME/gs-venv/bin"
|
2015-07-20 07:25:06 +00:00
|
|
|
```
|
|
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
2016-03-27 12:31:49 +00:00
|
|
|
|
2018-05-19 19:31:19 +00:00
|
|
|
Install on Ubuntu 14.04, 16.04, Debian 8 (jessie)
|
2017-10-24 17:14:57 +00:00
|
|
|
---
|
2017-12-07 02:26:12 +00:00
|
|
|
On Debian, use `su` to become root if `sudo` is not configured to give you access.
|
|
|
|
|
|
2016-03-27 12:31:49 +00:00
|
|
|
```
|
|
|
|
|
sudo apt-get update
|
2018-10-04 14:09:27 +00:00
|
|
|
sudo apt-get install --no-install-recommends git build-essential pkg-config libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev libxml2-dev libxslt1-dev libre2-dev
|
2017-12-07 02:26:12 +00:00
|
|
|
wget https://raw.githubusercontent.com/pyenv/pyenv-installer/master/bin/pyenv-installer
|
|
|
|
|
chmod +x pyenv-installer
|
|
|
|
|
./pyenv-installer
|
2018-10-04 15:01:36 +00:00
|
|
|
~/.pyenv/bin/pyenv install 3.7.0
|
|
|
|
|
~/.pyenv/versions/3.7.0/bin/python -m venv ~/gs-venv
|
2018-10-05 08:12:43 +00:00
|
|
|
~/gs-venv/bin/pip install --process-dependency-links --no-binary --upgrade git+https://github.com/ludios/grab-site
|
2017-02-04 13:36:47 +00:00
|
|
|
```
|
|
|
|
|
|
2017-11-22 17:24:47 +00:00
|
|
|
Add this to your `~/.bashrc` or `~/.zshrc` and then restart your shell (e.g. by opening a new terminal tab/window):
|
2017-02-04 13:36:47 +00:00
|
|
|
|
|
|
|
|
```
|
2017-10-24 17:24:27 +00:00
|
|
|
PATH="$PATH:$HOME/gs-venv/bin"
|
2017-02-04 13:36:47 +00:00
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2018-10-04 15:01:36 +00:00
|
|
|
Install on a non-Debian/Ubuntu distribution lacking Python 3.7.x
|
2015-12-20 00:00:13 +00:00
|
|
|
---
|
2018-10-04 14:09:27 +00:00
|
|
|
1. Install git, libxml2-dev, libxslt1-dev, and libre2-dev.
|
2015-12-20 00:00:13 +00:00
|
|
|
|
|
|
|
|
2. Install pyenv as described on https://github.com/yyuu/pyenv-installer#github-way-recommended
|
|
|
|
|
|
|
|
|
|
3. Install the packages needed to compile Python and its built-in sqlite3 module: https://github.com/yyuu/pyenv/wiki/Common-build-problems
|
|
|
|
|
|
2015-12-20 00:03:20 +00:00
|
|
|
4. Run:
|
|
|
|
|
|
2015-12-20 00:02:50 +00:00
|
|
|
```
|
2018-10-04 15:01:36 +00:00
|
|
|
~/.pyenv/bin/pyenv install 3.7.0
|
|
|
|
|
~/.pyenv/versions/3.7.0/bin/python -m venv ~/gs-venv
|
2018-10-05 08:12:43 +00:00
|
|
|
~/gs-venv/bin/pip install --process-dependency-links --no-binary --upgrade git+https://github.com/ludios/grab-site
|
2015-12-20 00:00:13 +00:00
|
|
|
```
|
|
|
|
|
|
2017-11-22 17:24:47 +00:00
|
|
|
5. Add this to your `~/.bashrc` or `~/.zshrc` and then restart your shell (e.g. by opening a new terminal tab/window):
|
2015-12-20 00:04:53 +00:00
|
|
|
|
|
|
|
|
```
|
2017-10-24 17:55:48 +00:00
|
|
|
PATH="$PATH:$HOME/gs-venv/bin"
|
2015-12-20 00:04:53 +00:00
|
|
|
```
|
|
|
|
|
|
2015-12-20 00:00:13 +00:00
|
|
|
|
|
|
|
|
|
2017-10-24 17:42:33 +00:00
|
|
|
Install on macOS
|
2015-07-20 06:35:32 +00:00
|
|
|
---
|
2017-10-24 17:42:33 +00:00
|
|
|
On OS X 10.10 - macOS 10.13:
|
2015-07-20 06:35:32 +00:00
|
|
|
|
2018-05-15 20:57:38 +00:00
|
|
|
1. Run `locale` in your terminal. If the output includes "UTF-8", you
|
|
|
|
|
are all set. If it does not, your terminal is misconfigured and grab-site
|
|
|
|
|
will fail to start. This can be corrected with:
|
2016-02-16 17:19:45 +00:00
|
|
|
|
|
|
|
|
- Terminal.app: Preferences... -> Profiles -> Advanced -> **check** Set locale environment variables on startup
|
|
|
|
|
|
2016-02-16 17:22:05 +00:00
|
|
|
- iTerm2: Preferences... -> Profiles -> Terminal -> Environment -> **check** Set locale variables automatically
|
2016-02-16 17:19:45 +00:00
|
|
|
|
2018-05-15 20:57:38 +00:00
|
|
|
2. Install Homebrew using the install step on https://brew.sh/
|
|
|
|
|
|
|
|
|
|
3. Run:
|
2017-10-24 17:42:33 +00:00
|
|
|
|
|
|
|
|
```
|
2018-05-15 20:57:38 +00:00
|
|
|
brew update
|
|
|
|
|
brew install pyenv
|
2018-10-04 15:01:36 +00:00
|
|
|
pyenv install 3.7.0
|
|
|
|
|
~/.pyenv/versions/3.7.0/bin/python -m venv ~/gs-venv
|
2018-10-05 08:12:43 +00:00
|
|
|
~/gs-venv/bin/pip install --process-dependency-links --no-binary --upgrade git+https://github.com/ludios/grab-site
|
2017-10-24 17:42:33 +00:00
|
|
|
```
|
2015-07-20 06:35:32 +00:00
|
|
|
|
2018-05-15 20:57:38 +00:00
|
|
|
4. Add this to your `~/.bash_profile` (which may not exist yet) and then restart your shell (e.g. by opening a new terminal tab/window):
|
2015-07-20 07:25:06 +00:00
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2017-10-24 17:42:33 +00:00
|
|
|
PATH="$PATH:$HOME/gs-venv/bin"
|
2015-07-20 07:25:06 +00:00
|
|
|
```
|
|
|
|
|
|
2015-07-20 06:35:32 +00:00
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
2017-10-24 16:43:10 +00:00
|
|
|
Install on Windows 10 (experimental)
|
|
|
|
|
---
|
|
|
|
|
On Windows 10 Fall Creators Update (1703) or newer:
|
|
|
|
|
|
|
|
|
|
1. Start menu -> search "feature" -> Turn Windows features on or off
|
|
|
|
|
|
|
|
|
|
2. Scroll down, check "Windows Subsystem for Linux" and click OK.
|
|
|
|
|
|
|
|
|
|
3. Wait for install and click "Restart now"
|
|
|
|
|
|
|
|
|
|
4. Start menu -> Store
|
|
|
|
|
|
|
|
|
|
5. Search for "Ubuntu" in the store and install Ubuntu (publisher: Canonical Group Limited).
|
|
|
|
|
|
|
|
|
|
6. Start menu -> Ubuntu
|
|
|
|
|
|
|
|
|
|
7. Wait for install and create a user when prompted.
|
|
|
|
|
|
2017-12-07 02:36:14 +00:00
|
|
|
8. Follow the [Ubuntu 14.04, 16.04, Debian 8 (jessie)](#install-on-ubuntu-1404-1604-debian-8-jessie) steps.
|
2017-10-24 16:43:10 +00:00
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2015-09-30 22:31:46 +00:00
|
|
|
Upgrade an existing install
|
|
|
|
|
---
|
2015-10-25 01:27:35 +00:00
|
|
|
|
2018-10-05 08:12:43 +00:00
|
|
|
To update grab-site, simply run the `~/gs-venv/bin/pip install ...` command used to install
|
2017-10-24 17:55:48 +00:00
|
|
|
it originally (see above).
|
2015-09-30 22:31:46 +00:00
|
|
|
|
2016-02-25 01:42:10 +00:00
|
|
|
After upgrading, stop `gs-server` with `kill` or ctrl-c, then start it again.
|
|
|
|
|
Existing `grab-site` crawls will automatically reconnect to the new server.
|
|
|
|
|
|
2015-09-30 22:31:46 +00:00
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
2015-03-09 04:48:27 +00:00
|
|
|
Usage
|
|
|
|
|
---
|
2015-07-18 12:06:00 +00:00
|
|
|
First, start the dashboard with:
|
|
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2017-10-24 17:14:57 +00:00
|
|
|
gs-server
|
2015-07-18 12:09:51 +00:00
|
|
|
```
|
2015-07-18 12:06:00 +00:00
|
|
|
|
|
|
|
|
and point your browser to http://127.0.0.1:29000/
|
|
|
|
|
|
2017-11-22 18:09:49 +00:00
|
|
|
Note: gs-server listens on all interfaces by default, so you can reach the
|
|
|
|
|
dashboard by a non-localhost IP as well, e.g. a LAN or WAN IP. (Sub-note:
|
|
|
|
|
no code execution capabilities are exposed on any interface.)
|
|
|
|
|
|
2015-07-18 12:06:00 +00:00
|
|
|
Then, start as many crawls as you want with:
|
|
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2017-10-24 17:14:57 +00:00
|
|
|
grab-site 'URL'
|
2015-02-05 04:27:38 +00:00
|
|
|
```
|
|
|
|
|
|
2015-07-18 12:06:00 +00:00
|
|
|
Do this inside tmux unless they're very short crawls.
|
2016-06-21 06:39:35 +00:00
|
|
|
Note that [tmux 2.1 is broken and will lock up frequently](https://github.com/tmux/tmux/issues/298).
|
2016-08-02 18:53:07 +00:00
|
|
|
Ubuntu 16.04 users probably need to remove tmux 2.1 and
|
|
|
|
|
[install tmux 1.8 from Ubuntu 14.04](https://gist.github.com/ivan/42597ad48c9f10cdd3c05418210e805b).
|
|
|
|
|
If you are unable to downgrade tmux, detaching immediately after starting the
|
|
|
|
|
crawl may be enough to avoid the problem.
|
2015-07-18 12:06:00 +00:00
|
|
|
|
2015-07-28 14:21:28 +00:00
|
|
|
grab-site outputs WARCs, logs, and control files to a new subdirectory in the
|
|
|
|
|
directory from which you launched `grab-site`, referred to here as "DIR".
|
|
|
|
|
(Use `ls -lrt` to find it.)
|
|
|
|
|
|
2016-02-26 05:46:28 +00:00
|
|
|
You can pass multiple `URL` arguments to include them in the same crawl,
|
|
|
|
|
whether they are on the same domain or different domains entirely.
|
|
|
|
|
|
2015-11-30 06:31:21 +00:00
|
|
|
warcprox users: [warcprox](https://github.com/internetarchive/warcprox) breaks the
|
|
|
|
|
dashboard's WebSocket; please make your browser skip the proxy for whichever
|
|
|
|
|
host/IP you're using to reach the dashboard.
|
|
|
|
|
|
2015-12-06 06:00:04 +00:00
|
|
|
### `grab-site` options, ordered by importance
|
2015-07-17 03:59:42 +00:00
|
|
|
|
2015-07-27 06:50:48 +00:00
|
|
|
Options can come before or after the URL.
|
2015-07-20 08:23:35 +00:00
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
* `--1`: grab just `URL` and its page requisites, without recursing.
|
2015-07-20 08:23:35 +00:00
|
|
|
|
2015-08-21 05:20:26 +00:00
|
|
|
* `--igsets=IGSET1,IGSET2`: use ignore sets `IGSET1` and `IGSET2`.
|
2015-07-20 08:23:35 +00:00
|
|
|
|
2015-07-27 13:28:49 +00:00
|
|
|
Ignore sets are used to avoid requesting junk URLs using a pre-made set of
|
2016-02-20 17:00:50 +00:00
|
|
|
regular expressions. See [the full list of available ignore sets](https://github.com/ludios/grab-site/tree/master/libgrabsite/ignore_sets).
|
2015-02-05 04:27:38 +00:00
|
|
|
|
2015-07-29 08:45:25 +00:00
|
|
|
The [global](https://github.com/ludios/grab-site/blob/master/libgrabsite/ignore_sets/global)
|
2015-07-20 08:29:37 +00:00
|
|
|
ignore set is implied and always enabled.
|
2015-07-20 08:25:33 +00:00
|
|
|
|
2015-07-28 14:01:28 +00:00
|
|
|
The ignore sets can be changed during the crawl by editing the `DIR/igsets` file.
|
|
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
* `--no-offsite-links`: avoid following links to a depth of 1 on other domains.
|
2015-03-09 05:06:44 +00:00
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
grab-site always grabs page requisites (e.g. inline images and stylesheets), even if
|
|
|
|
|
they are on other domains. By default, grab-site also grabs linked pages to a depth
|
|
|
|
|
of 1 on other domains. To turn off this behavior, use `--no-offsite-links`.
|
2015-02-05 19:31:50 +00:00
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
Using `--no-offsite-links` may prevent all kinds of useful images, video, audio, downloads,
|
|
|
|
|
etc from being grabbed, because these are often hosted on a CDN or subdomain, and
|
|
|
|
|
thus would otherwise not be included in the recursive crawl.
|
2015-03-09 05:06:44 +00:00
|
|
|
|
2015-08-12 05:39:16 +00:00
|
|
|
* `-i` / `--input-file`: Load list of URLs-to-grab from a local file or from a
|
|
|
|
|
URL; like `wget -i`. File must be a newline-delimited list of URLs.
|
|
|
|
|
Combine with `--1` to avoid a recursive crawl on each URL.
|
|
|
|
|
|
|
|
|
|
* `--igon`: Print all URLs being ignored to the terminal and dashboard. Can be
|
|
|
|
|
changed during the crawl by `touch`ing or `rm`ing the `DIR/igoff` file.
|
|
|
|
|
|
2015-08-21 08:28:27 +00:00
|
|
|
* `--no-video`: Skip the download of videos by both mime type and file extension.
|
|
|
|
|
Skipped videos are logged to `DIR/skipped_videos`. Can be
|
|
|
|
|
changed during the crawl by `touch`ing or `rm`ing the `DIR/video` file.
|
|
|
|
|
|
2015-08-12 05:39:16 +00:00
|
|
|
* `--no-sitemaps`: don't queue URLs from `sitemap.xml` at the root of the site.
|
2015-07-28 14:01:28 +00:00
|
|
|
|
2015-08-10 13:12:22 +00:00
|
|
|
* `--max-content-length=N`: Skip the download of any response that claims a
|
2015-09-02 19:15:00 +00:00
|
|
|
Content-Length larger than `N`. (default: -1, don't skip anything).
|
|
|
|
|
Skipped URLs are logged to `DIR/skipped_max_content_length`. Can be changed
|
|
|
|
|
during the crawl by editing the `DIR/max_content_length` file.
|
2015-08-10 13:12:22 +00:00
|
|
|
|
2015-09-30 22:16:56 +00:00
|
|
|
* `--no-dupespotter`: Disable dupespotter, a plugin that skips the extraction
|
|
|
|
|
of links from pages that look like duplicates of earlier pages. Disable this
|
|
|
|
|
for sites that are directory listings, because they frequently trigger false
|
|
|
|
|
positives.
|
|
|
|
|
|
2015-08-12 05:39:16 +00:00
|
|
|
* `--concurrency=N`: Use `N` connections to fetch in parallel (default: 2).
|
|
|
|
|
Can be changed during the crawl by editing the `DIR/concurrency` file.
|
2015-08-10 13:23:43 +00:00
|
|
|
|
2015-08-12 05:39:16 +00:00
|
|
|
* `--delay=N`: Wait `N` milliseconds (default: 0) between requests on each concurrent fetcher.
|
|
|
|
|
Can be a range like X-Y to use a random delay between X and Y. Can be changed during
|
|
|
|
|
the crawl by editing the `DIR/delay` file.
|
2015-08-12 05:24:09 +00:00
|
|
|
|
2017-12-27 13:48:20 +00:00
|
|
|
* `--import-ignores`: Copy this file to to `DIR/ignores` before the crawl begins.
|
|
|
|
|
|
2015-08-21 07:47:12 +00:00
|
|
|
* `--warc-max-size=BYTES`: Try to limit each WARC file to around `BYTES` bytes
|
2016-02-21 00:23:18 +00:00
|
|
|
before rolling over to a new WARC file (default: 5368709120, which is 5GiB).
|
|
|
|
|
Note that the resulting WARC files may be drastically larger if there are very
|
|
|
|
|
large responses.
|
2015-08-21 07:47:12 +00:00
|
|
|
|
2015-07-27 06:50:48 +00:00
|
|
|
* `--level=N`: recurse `N` levels instead of `inf` levels.
|
|
|
|
|
|
|
|
|
|
* `--page-requisites-level=N`: recurse page requisites `N` levels instead of `5` levels.
|
|
|
|
|
|
2018-07-07 12:01:10 +00:00
|
|
|
* `--ua=STRING`: Send User-Agent: `STRING` instead of pretending to be Firefox on Windows.
|
2015-08-10 13:38:00 +00:00
|
|
|
|
2015-12-12 19:52:32 +00:00
|
|
|
* `--id=ID`: Use id `ID` for the crawl instead of a random 128-bit id. This must be unique for every crawl.
|
|
|
|
|
|
|
|
|
|
* `--dir=DIR`: Put control files, temporary files, and unfinished WARCs in `DIR`
|
|
|
|
|
(default: a directory name based on the URL, date, and first 8 characters of the id).
|
|
|
|
|
|
|
|
|
|
* `--finished-warc-dir=FINISHED_WARC_DIR`: Move finished `.warc.gz` and `.cdx` files to this directory.
|
|
|
|
|
|
2017-02-08 20:23:12 +00:00
|
|
|
* `--permanent-error-status-codes=STATUS_CODES`: A comma-separated list of
|
|
|
|
|
HTTP status codes to treat as a permanent error and therefore **not** retry
|
|
|
|
|
(default: `401,403,404,405,410`). Other error responses tried another 2
|
|
|
|
|
times for a total of 3 tries (customizable with `--wpull-args=--tries=N`).
|
|
|
|
|
Note that, unlike wget, wpull puts retries at the end of the queue.
|
|
|
|
|
|
2015-08-12 06:39:49 +00:00
|
|
|
* `--wpull-args=ARGS`: String containing additional arguments to pass to wpull;
|
2017-10-24 17:14:57 +00:00
|
|
|
see `wpull --help`. `ARGS` is split with `shlex.split` and individual
|
2015-08-12 06:39:49 +00:00
|
|
|
arguments can contain spaces if quoted, e.g.
|
|
|
|
|
`--wpull-args="--youtube-dl \"--youtube-dl-exe=/My Documents/youtube-dl\""`
|
|
|
|
|
|
2015-10-07 08:13:19 +00:00
|
|
|
Also useful: `--wpull-args=--no-skip-getaddrinfo` to respect `/etc/hosts` entries.
|
|
|
|
|
|
2016-02-21 05:06:16 +00:00
|
|
|
* `--which-wpull-args-partial`: Print a partial list of wpull arguments that
|
|
|
|
|
would be used and exit. Excludes grab-site-specific features, and removes
|
|
|
|
|
`DIR/` from paths. Useful for reporting bugs on wpull without grab-site involvement.
|
|
|
|
|
|
|
|
|
|
* `--which-wpull-command`: Populate `DIR/` but don't start wpull; instead print
|
|
|
|
|
the command that would have been used to start wpull with all of the
|
|
|
|
|
grab-site functionality.
|
|
|
|
|
|
2018-10-05 16:09:11 +00:00
|
|
|
* `--debug`: print a lot of debug information.
|
|
|
|
|
|
2015-07-27 06:50:48 +00:00
|
|
|
* `--help`: print help text.
|
2015-03-09 05:06:44 +00:00
|
|
|
|
2016-02-17 21:49:35 +00:00
|
|
|
### Warnings
|
|
|
|
|
|
2018-10-05 16:16:04 +00:00
|
|
|
If you pay no attention to your crawls, a crawl may head down some infinite bot
|
|
|
|
|
trap and stay there forever. The site owner may eventually notice high CPU use
|
|
|
|
|
or log activity, then IP-ban you.
|
|
|
|
|
|
|
|
|
|
grab-site does not respect `robots.txt` files, because they frequently
|
|
|
|
|
[whitelist only approved robots](https://github.com/robots.txt),
|
|
|
|
|
[hide pages embarrassing to the site owner](https://web.archive.org/web/20140401024610/http://www.thecrimson.com/robots.txt),
|
|
|
|
|
or block image or stylesheet resources needed for proper archival.
|
|
|
|
|
[See also](http://www.archiveteam.org/index.php?title=Robots.txt).
|
|
|
|
|
Because of this, very rarely you might run into a robot honeypot and receive
|
|
|
|
|
an abuse@ complaint. Your host may require a prompt response to such a complaint
|
|
|
|
|
for your server to stay online. Therefore, we recommend against crawling the
|
|
|
|
|
web from a server that hosts your critical infrastructure.
|
|
|
|
|
|
|
|
|
|
Don't run grab-site on GCE (Google Compute Engine); as happened to me, your
|
|
|
|
|
entire API project may get nuked after a few days of crawling the web, with
|
|
|
|
|
no recourse. Good alternatives include OVH ([OVH](https://www.ovh.com/us/dedicated-servers/),
|
|
|
|
|
[So You Start](http://www.soyoustart.com/us/essential-servers/),
|
|
|
|
|
[Kimsufi](http://www.kimsufi.com/us/en/index.xml)), and online.net's
|
|
|
|
|
[dedicated](https://www.online.net/en/dedicated-server) and
|
|
|
|
|
[Scaleway](https://www.scaleway.com/) offerings.
|
2016-02-17 21:49:35 +00:00
|
|
|
|
2015-12-11 08:39:36 +00:00
|
|
|
### Tips for specific websites
|
|
|
|
|
|
2017-11-09 11:10:54 +00:00
|
|
|
#### Website requiring login / cookies
|
|
|
|
|
|
2018-10-05 16:16:54 +00:00
|
|
|
Log in to the website in Chrome or Firefox. Use the cookies.txt extension
|
|
|
|
|
[for Chrome](https://github.com/daftano/cookies.txt) or
|
|
|
|
|
[for Firefox](https://addons.mozilla.org/en-US/firefox/addon/cookies-txt/)
|
|
|
|
|
extension to copy Netscape-format cookies. Paste the cookies data into a new
|
|
|
|
|
file. Start grab-site with `--wpull-args=--load-cookies=ABSOLUTE_PATH_TO_COOKIES_FILE`.
|
2017-11-09 11:10:54 +00:00
|
|
|
|
2016-01-11 04:51:23 +00:00
|
|
|
#### Static websites; WordPress blogs; Discourse forums
|
2015-12-11 08:39:36 +00:00
|
|
|
|
|
|
|
|
The defaults usually work fine.
|
|
|
|
|
|
2015-12-11 08:40:30 +00:00
|
|
|
#### Blogger / blogspot.com blogs
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2015-12-12 18:35:20 +00:00
|
|
|
The defaults work fine except for blogs with a JavaScript-only Dynamic Views theme.
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2018-10-05 16:16:54 +00:00
|
|
|
Some blogspot.com blogs use "[Dynamic Views](https://support.google.com/blogger/answer/1229061?hl=en)"
|
|
|
|
|
themes that require JavaScript and serve absolutely no HTML content. In rare
|
|
|
|
|
cases, you can get JavaScript-free pages by appending `?m=1`
|
|
|
|
|
([example](http://happinessbeyondthought.blogspot.com/?m=1)). Otherwise, you
|
|
|
|
|
can archive parts of these blogs through Google Cache instead
|
|
|
|
|
([example](https://webcache.googleusercontent.com/search?q=cache:http://blog.datomic.com/))
|
2018-10-05 16:17:02 +00:00
|
|
|
or by using http://archive.is/ instead of grab-site.
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2015-12-11 08:40:30 +00:00
|
|
|
#### Tumblr blogs
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2018-10-05 16:17:43 +00:00
|
|
|
Don't crawl from Europe: tumblr redirects to a GDPR `/privacy/consent` page and
|
|
|
|
|
the `Googlebot` user agent override no longer has any effect.
|
2018-07-07 12:04:11 +00:00
|
|
|
|
2018-10-05 16:17:43 +00:00
|
|
|
Use [`--igsets=singletumblr`](https://github.com/ludios/grab-site/blob/master/libgrabsite/ignore_sets/singletumblr)
|
|
|
|
|
to avoid crawling the homepages of other tumblr blogs.
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2018-10-05 16:17:43 +00:00
|
|
|
If you don't care about who liked or reblogged a post, add `\?from_c=` to the
|
|
|
|
|
crawl's `ignores`.
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2018-10-05 16:17:43 +00:00
|
|
|
Some tumblr blogs appear to require JavaScript, but they are actually just
|
|
|
|
|
hiding the page content with CSS. You are still likely to get a complete crawl.
|
|
|
|
|
(See the links in the page source for http://X.tumblr.com/archive).
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2015-12-11 08:48:18 +00:00
|
|
|
#### Subreddits
|
|
|
|
|
|
2018-10-05 16:18:06 +00:00
|
|
|
Use [`--igsets=reddit`](https://github.com/ludios/grab-site/blob/master/libgrabsite/ignore_sets/reddit)
|
|
|
|
|
and add a `/` at the end of the URL to avoid crawling all subreddits.
|
2015-12-11 08:48:18 +00:00
|
|
|
|
2018-10-05 16:18:06 +00:00
|
|
|
When crawling a subreddit, you **must** get the casing of the subreddit right
|
|
|
|
|
for the recursive crawl to work. For example,
|
2015-12-11 08:48:18 +00:00
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2015-12-11 08:48:18 +00:00
|
|
|
grab-site https://www.reddit.com/r/Oculus/ --igsets=reddit
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
will crawl only a few pages instead of the entire subreddit. The correct casing is:
|
|
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2015-12-11 08:48:18 +00:00
|
|
|
grab-site https://www.reddit.com/r/oculus/ --igsets=reddit
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
You can hover over the "Hot"/"New"/... links at the top of the page to see the correct casing.
|
|
|
|
|
|
2015-12-11 08:40:30 +00:00
|
|
|
#### Directory listings ("Index of ...")
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2018-10-05 16:18:06 +00:00
|
|
|
Use `--no-dupespotter` to avoid triggering false positives on the duplicate
|
|
|
|
|
page detector. Without it, the crawl may miss large parts of the directory tree.
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2015-12-11 08:40:30 +00:00
|
|
|
#### Very large websites
|
2015-12-11 08:39:36 +00:00
|
|
|
|
|
|
|
|
Use `--no-offsite-links` to stay on the main website and avoid crawling linked pages on other domains.
|
|
|
|
|
|
2015-12-11 08:40:30 +00:00
|
|
|
#### Websites that are likely to ban you for crawling fast
|
2015-12-11 08:39:36 +00:00
|
|
|
|
|
|
|
|
Use `--concurrency=1 --delay=500-1500`.
|
|
|
|
|
|
2015-12-11 08:40:30 +00:00
|
|
|
#### MediaWiki sites with English language
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2018-10-05 16:19:05 +00:00
|
|
|
Use [`--igsets=mediawiki`](https://github.com/ludios/grab-site/blob/master/libgrabsite/ignore_sets/mediawiki).
|
|
|
|
|
Note that this ignore set ignores old page revisions.
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2015-12-11 08:40:30 +00:00
|
|
|
#### MediaWiki sites with non-English language
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2018-10-05 16:19:05 +00:00
|
|
|
You will probably have to add ignores with translated `Special:*` URLs based on
|
|
|
|
|
[ignore_sets/mediawiki](https://github.com/ludios/grab-site/blob/master/libgrabsite/ignore_sets/mediawiki).
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2016-01-11 04:51:23 +00:00
|
|
|
#### Forums that aren't Discourse
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2018-10-05 16:19:05 +00:00
|
|
|
Forums require more manual intervention with ignore patterns.
|
|
|
|
|
[`--igsets=forums`](https://github.com/ludios/grab-site/blob/master/libgrabsite/ignore_sets/forums)
|
|
|
|
|
is often useful for non-SMF forums, but you will have to add other ignore
|
|
|
|
|
patterns, including one to ignore individual-forum-post pages if there are
|
|
|
|
|
too many posts to crawl. (Generally, crawling the thread pages is enough.)
|
2015-12-11 08:39:36 +00:00
|
|
|
|
2016-01-09 22:00:42 +00:00
|
|
|
#### GitHub issues / pull requests
|
|
|
|
|
|
|
|
|
|
Find the highest issue number from an issues page ([example](https://github.com/rust-lang/rust/issues)) and use:
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
grab-site --1 https://github.com/rust-lang/rust/issues/{1..30000}
|
|
|
|
|
```
|
|
|
|
|
|
2018-10-05 16:19:05 +00:00
|
|
|
This relies on your shell to expand the argument to thousands of arguments.
|
|
|
|
|
If there are too many arguments, you may have to write the URLs to a file
|
|
|
|
|
and use `grab-site -i` instead:
|
2016-01-09 22:00:42 +00:00
|
|
|
|
|
|
|
|
```
|
|
|
|
|
for i in {1..30000}; do echo https://github.com/rust-lang/rust/issues/$i >> .urls; done
|
|
|
|
|
grab-site --1 -i .urls
|
|
|
|
|
```
|
|
|
|
|
|
2015-12-11 08:56:27 +00:00
|
|
|
#### Websites whose domains have just expired but are still up at the webhost
|
2015-12-11 08:54:09 +00:00
|
|
|
|
2018-10-05 16:19:05 +00:00
|
|
|
Use a [DNS history](https://www.google.com/search?q=historical+OR+history+dns)
|
|
|
|
|
service to find the old IP address (the DNS "A" record) for the domain. Add a
|
|
|
|
|
line to your `/etc/hosts` to point the domain to the old IP. Start a crawl
|
|
|
|
|
with `--wpull-args=--no-skip-getaddrinfo` to make wpull use `/etc/hosts`.
|
2015-12-11 08:54:09 +00:00
|
|
|
|
2016-01-07 07:28:23 +00:00
|
|
|
#### twitter.com/user
|
|
|
|
|
|
2018-10-05 16:19:05 +00:00
|
|
|
Use [webrecorder.io](https://webrecorder.io/) instead of grab-site. Enter a
|
|
|
|
|
URL, then hit the 'Auto Scroll' button at the top. Wait until it's done and
|
|
|
|
|
unpress the Auto Scroll button. Click the 'N MB' icon at the top and download
|
|
|
|
|
your WARC file.
|
2016-01-07 07:28:23 +00:00
|
|
|
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
2015-03-09 04:48:27 +00:00
|
|
|
Changing ignores during the crawl
|
|
|
|
|
---
|
2015-07-18 06:23:24 +00:00
|
|
|
While the crawl is running, you can edit `DIR/ignores` and `DIR/igsets`; the
|
2015-07-30 23:36:12 +00:00
|
|
|
changes will be applied within a few seconds.
|
2015-02-05 04:59:28 +00:00
|
|
|
|
2015-07-18 06:23:24 +00:00
|
|
|
`DIR/igsets` is a comma-separated list of ignore sets to use.
|
2015-02-05 05:37:34 +00:00
|
|
|
|
2015-02-05 19:31:50 +00:00
|
|
|
`DIR/ignores` is a newline-separated list of [Python 3 regular expressions](http://pythex.org/)
|
|
|
|
|
to use in addition to the ignore sets.
|
2015-02-05 05:37:34 +00:00
|
|
|
|
2015-07-18 08:23:56 +00:00
|
|
|
You can `rm DIR/igoff` to display all URLs that are being filtered out
|
|
|
|
|
by the ignores, and `touch DIR/igoff` to turn it back off.
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2018-08-06 23:34:00 +00:00
|
|
|
Note that ignores will not apply to any of the crawl's start URLs.
|
|
|
|
|
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
2015-07-28 11:33:51 +00:00
|
|
|
Inspecting the URL queue
|
|
|
|
|
---
|
|
|
|
|
Inspecting the URL queue is usually not necessary, but may be helpful
|
2015-07-31 03:50:39 +00:00
|
|
|
for adding ignores before grab-site crawls a large number of junk URLs.
|
2015-07-28 11:33:51 +00:00
|
|
|
|
2015-07-28 11:34:58 +00:00
|
|
|
To dump the queue, run:
|
2015-07-28 11:33:51 +00:00
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2017-10-24 17:14:57 +00:00
|
|
|
gs-dump-urls DIR/wpull.db todo
|
2015-07-28 11:33:51 +00:00
|
|
|
```
|
|
|
|
|
|
|
|
|
|
Four other statuses can be used besides `todo`:
|
|
|
|
|
`done`, `error`, `in_progress`, and `skipped`.
|
|
|
|
|
|
2015-07-28 11:40:14 +00:00
|
|
|
You may want to pipe the output to `sort` and `less`:
|
|
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2017-10-24 17:14:57 +00:00
|
|
|
gs-dump-urls DIR/wpull.db todo | sort | less -S
|
2015-07-28 11:40:14 +00:00
|
|
|
```
|
|
|
|
|
|
2015-07-28 11:33:51 +00:00
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
2018-08-28 01:30:35 +00:00
|
|
|
Preventing a crawl from queuing any more URLs
|
|
|
|
|
---
|
|
|
|
|
`rm DIR/scrape`. Responses will no longer be scraped for URLs. Scraping cannot
|
|
|
|
|
be re-enabled for a crawl.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2015-07-18 10:51:17 +00:00
|
|
|
Stopping a crawl
|
|
|
|
|
---
|
|
|
|
|
You can `touch DIR/stop` or press ctrl-c, which will do the same. You will
|
|
|
|
|
have to wait for the current downloads to finish.
|
|
|
|
|
|
|
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
2015-07-18 12:06:00 +00:00
|
|
|
Advanced `gs-server` options
|
2015-07-18 06:16:46 +00:00
|
|
|
---
|
2015-07-18 12:06:00 +00:00
|
|
|
These environmental variables control what `gs-server` listens on:
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2016-02-25 01:09:07 +00:00
|
|
|
* `GRAB_SITE_INTERFACE` (default `0.0.0.0`)
|
2016-05-22 11:06:38 +00:00
|
|
|
* `GRAB_SITE_PORT` (default `29000`)
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-07-18 06:22:47 +00:00
|
|
|
These environmental variables control which server each `grab-site` process connects to:
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2016-02-25 01:09:07 +00:00
|
|
|
* `GRAB_SITE_HOST` (default `127.0.0.1`)
|
|
|
|
|
* `GRAB_SITE_PORT` (default `29000`)
|
2015-07-19 20:15:23 +00:00
|
|
|
|
|
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
2015-07-20 09:47:22 +00:00
|
|
|
Viewing the content in your WARC archives
|
|
|
|
|
---
|
|
|
|
|
You can use [ikreymer/webarchiveplayer](https://github.com/ikreymer/webarchiveplayer)
|
|
|
|
|
to view the content inside your WARC archives. It requires Python 2, so install it with
|
|
|
|
|
`pip` instead of `pip3`:
|
|
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2015-07-20 09:47:22 +00:00
|
|
|
sudo apt-get install --no-install-recommends git build-essential python-dev python-pip
|
|
|
|
|
pip install --user git+https://github.com/ikreymer/webarchiveplayer
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
And use it with:
|
|
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2015-07-20 09:47:22 +00:00
|
|
|
~/.local/bin/webarchiveplayer <path to WARC>
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
then point your browser to http://127.0.0.1:8090/
|
|
|
|
|
|
|
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
|
|
|
|
Inspecting WARC files in the terminal
|
|
|
|
|
---
|
|
|
|
|
`zless` is a wrapper over `less` that can be used to view raw WARC content:
|
|
|
|
|
|
2015-12-17 15:19:20 +00:00
|
|
|
```
|
2015-10-11 06:35:39 +00:00
|
|
|
zless DIR/FILE.warc.gz
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
`zless -S` will turn off line wrapping.
|
|
|
|
|
|
2018-10-05 16:13:37 +00:00
|
|
|
Note that grab-site requests uncompressed HTTP responses to avoid
|
|
|
|
|
double-compression in .warc.gz files and to make zless output more useful.
|
|
|
|
|
However, some servers will send compressed responses anyway.
|
2015-10-11 06:35:39 +00:00
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2016-02-08 20:15:51 +00:00
|
|
|
Automatically pausing grab-site processes when free disk is low
|
2016-02-08 20:09:32 +00:00
|
|
|
---
|
|
|
|
|
|
2018-10-05 16:13:37 +00:00
|
|
|
If you automatically upload and remove finished .warc.gz files, you can still
|
|
|
|
|
run into a situation where grab-site processes fill up your disk faster than
|
|
|
|
|
your uploader process can handle. To prevent this situation, you can customize
|
|
|
|
|
and run [this script](https://github.com/ludios/grab-site/blob/master/extra_docs/pause_resume_grab_sites.sh),
|
|
|
|
|
which will pause and resume grab-site processes as your free disk space
|
|
|
|
|
crosses a threshold value.
|
2016-02-08 20:09:32 +00:00
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2015-07-27 07:59:57 +00:00
|
|
|
Thanks
|
|
|
|
|
---
|
|
|
|
|
grab-site is made possible only because of [wpull](https://github.com/chfoo/wpull),
|
|
|
|
|
written by [Christopher Foo](https://github.com/chfoo) who spent a year
|
|
|
|
|
making something much better than wget. ArchiveTeam's most pressing
|
|
|
|
|
issue with wget at the time was that it kept the entire URL queue in memory
|
|
|
|
|
instead of on disk. wpull has many other advantages over wget, including
|
|
|
|
|
better link extraction and Python hooks.
|
|
|
|
|
|
2015-07-31 03:52:42 +00:00
|
|
|
Thanks to [David Yip](https://github.com/yipdw), who created
|
|
|
|
|
[ArchiveBot](https://github.com/ArchiveTeam/ArchiveBot). The wpull
|
2015-07-29 08:55:06 +00:00
|
|
|
hooks in ArchiveBot served as the basis for grab-site. The original ArchiveBot
|
|
|
|
|
dashboard inspired the newer dashboard now used in both projects.
|
2015-07-27 07:59:57 +00:00
|
|
|
|
2018-10-05 16:12:15 +00:00
|
|
|
Thanks to [JustAnotherArchivist](https://github.com/JustAnotherArchivist)
|
|
|
|
|
for investigating my wpull issues.
|
|
|
|
|
|
2015-07-27 07:59:57 +00:00
|
|
|
|
2015-10-11 06:35:39 +00:00
|
|
|
|
2015-07-19 20:15:23 +00:00
|
|
|
Help
|
|
|
|
|
---
|
2018-10-05 16:19:55 +00:00
|
|
|
grab-site bugs and questions are welcome in
|
|
|
|
|
[grab-site/issues](https://github.com/ludios/grab-site/issues).
|
2017-03-09 07:58:28 +00:00
|
|
|
Please report security bugs as regular bugs.
|
2015-07-19 20:15:23 +00:00
|
|
|
|
2016-02-21 05:06:16 +00:00
|
|
|
Terminal output in your bug report should be surrounded by triple backquotes, like this:
|
|
|
|
|
|
2016-02-21 05:10:34 +00:00
|
|
|
<pre>
|
2016-02-21 05:06:16 +00:00
|
|
|
```
|
|
|
|
|
very
|
|
|
|
|
long
|
|
|
|
|
output
|
|
|
|
|
```
|
2016-02-21 05:10:34 +00:00
|
|
|
</pre>
|
2015-12-12 17:58:52 +00:00
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
[travis-image]: https://img.shields.io/travis/ludios/grab-site.svg
|
|
|
|
|
[travis-url]: https://travis-ci.org/ludios/grab-site
|