2015-03-09 04:48:27 +00:00
|
|
|
grab-site
|
|
|
|
|
===
|
|
|
|
|
|
2015-03-09 04:52:18 +00:00
|
|
|
grab-site is an easy preconfigured web crawler designed for backing up websites. Give
|
2015-07-18 09:54:07 +00:00
|
|
|
grab-site a URL and it will recursively crawl the site and write
|
|
|
|
|
[WARC files](http://www.archiveteam.org/index.php?title=The_WARC_Ecosystem).
|
2015-03-09 04:53:38 +00:00
|
|
|
|
2015-07-18 09:54:07 +00:00
|
|
|
grab-site uses [wpull](https://github.com/chfoo/wpull) for crawling.
|
|
|
|
|
The wpull options are preconfigured based on Archive Team's experience with
|
|
|
|
|
[ArchiveBot](https://github.com/ArchiveTeam/ArchiveBot).
|
2015-03-09 04:48:27 +00:00
|
|
|
|
2015-07-18 09:54:07 +00:00
|
|
|
grab-site gives you
|
|
|
|
|
|
2015-07-18 11:25:00 +00:00
|
|
|
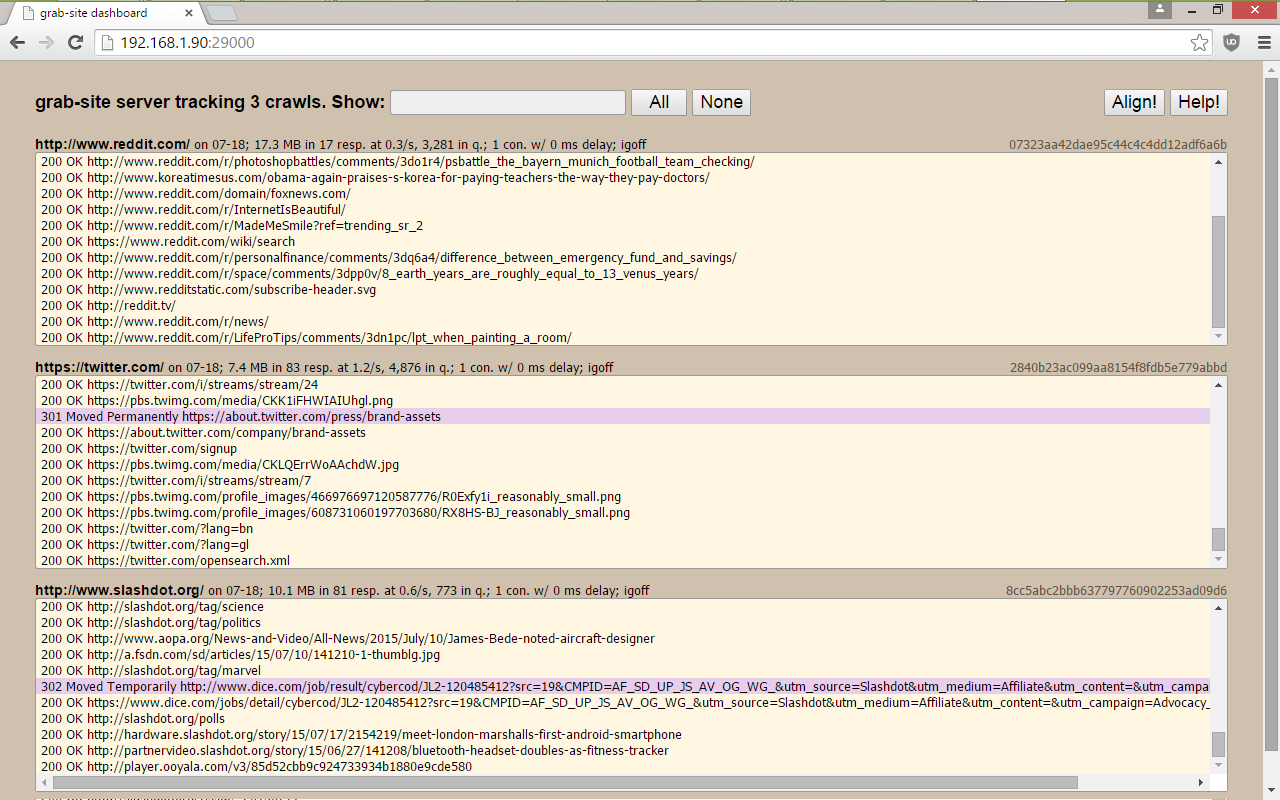
* a dashboard with all of your crawls, showing which URLs are being
|
2015-07-18 09:54:07 +00:00
|
|
|
grabbed, how many URLs are left in the queue, and more.
|
|
|
|
|
|
|
|
|
|
* the ability to add ignore patterns when the crawl is already running.
|
|
|
|
|
This allows you to skip the crawling of junk URLs that would
|
|
|
|
|
otherwise prevent your crawl from ever finishing. See below.
|
2015-03-09 04:48:27 +00:00
|
|
|
|
2015-07-18 09:58:17 +00:00
|
|
|
* an extensively tested default ignore set ("[global](https://github.com/ArchiveTeam/ArchiveBot/blob/master/db/ignore_patterns/global.json)")
|
|
|
|
|
as well as additional (optional) ignore sets for blogs, forums, etc.
|
|
|
|
|
|
2015-07-18 10:02:10 +00:00
|
|
|
* duplicate page detection: links are not followed on pages whose
|
2015-07-18 10:01:25 +00:00
|
|
|
content duplicates an already-seen page.
|
|
|
|
|
|
2015-07-27 07:59:57 +00:00
|
|
|
The URL queue is kept on disk instead of in memory. If you're really lucky,
|
|
|
|
|
grab-site will manage to crawl a site with ~10M pages.
|
|
|
|
|
|
2015-07-18 11:22:28 +00:00
|
|
|
|
2015-07-18 11:19:07 +00:00
|
|
|
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-07-20 06:35:32 +00:00
|
|
|
Install on Ubuntu
|
2015-03-09 04:48:27 +00:00
|
|
|
---
|
|
|
|
|
|
2015-02-05 04:27:38 +00:00
|
|
|
On Ubuntu 14.04.1 or newer:
|
|
|
|
|
|
2015-02-05 04:25:49 +00:00
|
|
|
```
|
2015-02-05 19:27:19 +00:00
|
|
|
sudo apt-get install --no-install-recommends git build-essential python3-dev python3-pip
|
2015-07-18 10:41:24 +00:00
|
|
|
pip3 install --user git+https://github.com/ludios/grab-site
|
2015-02-05 04:25:49 +00:00
|
|
|
```
|
|
|
|
|
|
2015-07-20 07:50:49 +00:00
|
|
|
To avoid having to type out `~/.local/bin/` below, add this to your
|
|
|
|
|
`~/.bashrc` or `~/.zshrc`:
|
2015-07-20 07:25:06 +00:00
|
|
|
|
|
|
|
|
```
|
|
|
|
|
PATH="$PATH:$HOME/.local/bin"
|
|
|
|
|
```
|
|
|
|
|
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-07-20 06:35:32 +00:00
|
|
|
Install on OS X
|
|
|
|
|
---
|
|
|
|
|
|
|
|
|
|
On OS X 10.10:
|
|
|
|
|
|
2015-07-20 07:50:49 +00:00
|
|
|
1. If xcode is not already installed, type `gcc` in Terminal; you will be
|
|
|
|
|
prompted to install the command-line developer tools. Click 'Install'.
|
2015-07-20 06:35:32 +00:00
|
|
|
|
2015-07-20 07:50:49 +00:00
|
|
|
2. If Python 3 is not already installed, install Python 3.4.3 using the
|
|
|
|
|
installer from https://www.python.org/downloads/release/python-343/
|
2015-07-20 06:35:32 +00:00
|
|
|
|
|
|
|
|
3. `pip3 install --user git+https://github.com/ludios/grab-site`
|
|
|
|
|
|
2015-07-20 07:50:49 +00:00
|
|
|
**Important usage note**: Use `~/Library/Python/3.4/bin/` instead of
|
|
|
|
|
`~/.local/bin/` for all instructions below!
|
2015-07-20 06:35:32 +00:00
|
|
|
|
2015-07-20 07:50:49 +00:00
|
|
|
To avoid having to type out `~/Library/Python/3.4/bin/` below,
|
|
|
|
|
add this to your `~/.bash_profile` (which may not exist yet):
|
2015-07-20 07:25:06 +00:00
|
|
|
|
|
|
|
|
```
|
|
|
|
|
PATH="$PATH:$HOME/Library/Python/3.4/bin"
|
|
|
|
|
```
|
|
|
|
|
|
2015-07-20 06:35:32 +00:00
|
|
|
|
2015-03-09 04:48:27 +00:00
|
|
|
Usage
|
|
|
|
|
---
|
2015-07-18 12:06:00 +00:00
|
|
|
First, start the dashboard with:
|
|
|
|
|
|
2015-07-18 12:09:51 +00:00
|
|
|
```
|
|
|
|
|
~/.local/bin/gs-server
|
|
|
|
|
```
|
2015-07-18 12:06:00 +00:00
|
|
|
|
|
|
|
|
and point your browser to http://127.0.0.1:29000/
|
|
|
|
|
|
|
|
|
|
Then, start as many crawls as you want with:
|
|
|
|
|
|
2015-02-05 04:27:38 +00:00
|
|
|
```
|
2015-07-18 10:41:24 +00:00
|
|
|
~/.local/bin/grab-site URL
|
2015-02-05 04:27:38 +00:00
|
|
|
```
|
|
|
|
|
|
2015-07-18 12:06:00 +00:00
|
|
|
Do this inside tmux unless they're very short crawls.
|
|
|
|
|
|
2015-07-20 08:30:57 +00:00
|
|
|
### Options
|
2015-07-17 03:59:42 +00:00
|
|
|
|
2015-07-27 06:50:48 +00:00
|
|
|
Options can come before or after the URL.
|
2015-07-20 08:23:35 +00:00
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
* `--1`: grab just `URL` and its page requisites, without recursing.
|
2015-07-20 08:23:35 +00:00
|
|
|
|
2015-07-27 07:38:06 +00:00
|
|
|
* `--concurrency=N`: Use N connections to fetch in parallel (default: 2).
|
2015-07-20 09:30:51 +00:00
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
* `--igsets=blogs,forums`: use ignore sets `blogs` and `forums`.
|
2015-07-20 08:23:35 +00:00
|
|
|
|
2015-07-27 13:28:49 +00:00
|
|
|
Ignore sets are used to avoid requesting junk URLs using a pre-made set of
|
|
|
|
|
regular expressions.
|
2015-07-20 08:23:35 +00:00
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
`forums` and `blogs` are some frequently-used ignore sets.
|
|
|
|
|
See [the full list of available ignore sets](https://github.com/ArchiveTeam/ArchiveBot/tree/master/db/ignore_patterns).
|
2015-02-05 04:27:38 +00:00
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
The [global](https://github.com/ArchiveTeam/ArchiveBot/blob/master/db/ignore_patterns/global.json)
|
|
|
|
|
ignore set is implied and always enabled.
|
2015-07-20 08:25:33 +00:00
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
* `--no-offsite-links`: avoid following links to a depth of 1 on other domains.
|
2015-03-09 05:06:44 +00:00
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
grab-site always grabs page requisites (e.g. inline images and stylesheets), even if
|
|
|
|
|
they are on other domains. By default, grab-site also grabs linked pages to a depth
|
|
|
|
|
of 1 on other domains. To turn off this behavior, use `--no-offsite-links`.
|
2015-02-05 19:31:50 +00:00
|
|
|
|
2015-07-20 08:29:37 +00:00
|
|
|
Using `--no-offsite-links` may prevent all kinds of useful images, video, audio, downloads,
|
|
|
|
|
etc from being grabbed, because these are often hosted on a CDN or subdomain, and
|
|
|
|
|
thus would otherwise not be included in the recursive crawl.
|
2015-03-09 05:06:44 +00:00
|
|
|
|
2015-07-27 06:50:48 +00:00
|
|
|
* `--level=N`: recurse `N` levels instead of `inf` levels.
|
|
|
|
|
|
|
|
|
|
* `--page-requisites-level=N`: recurse page requisites `N` levels instead of `5` levels.
|
|
|
|
|
|
2015-07-27 06:55:20 +00:00
|
|
|
* `--no-sitemaps`: don't queue URLs from `sitemap.xml` at the root of the site.
|
|
|
|
|
|
2015-07-27 06:50:48 +00:00
|
|
|
* `--help`: print help text.
|
2015-03-09 05:06:44 +00:00
|
|
|
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-03-09 04:48:27 +00:00
|
|
|
Changing ignores during the crawl
|
|
|
|
|
---
|
2015-07-20 09:53:13 +00:00
|
|
|
grab-site outputs WARCs, logs, and control files to a new subdirectory in the
|
2015-07-20 08:04:14 +00:00
|
|
|
directory from which you launched `grab-site`, referred to here as "DIR".
|
|
|
|
|
(Use `ls -lrt` to find it.)
|
2015-03-09 04:48:27 +00:00
|
|
|
|
2015-07-18 06:23:24 +00:00
|
|
|
While the crawl is running, you can edit `DIR/ignores` and `DIR/igsets`; the
|
2015-02-05 04:59:28 +00:00
|
|
|
changes will be applied as soon as the next URL is grabbed.
|
|
|
|
|
|
2015-07-18 06:23:24 +00:00
|
|
|
`DIR/igsets` is a comma-separated list of ignore sets to use.
|
2015-02-05 05:37:34 +00:00
|
|
|
|
2015-02-05 19:31:50 +00:00
|
|
|
`DIR/ignores` is a newline-separated list of [Python 3 regular expressions](http://pythex.org/)
|
|
|
|
|
to use in addition to the ignore sets.
|
2015-02-05 05:37:34 +00:00
|
|
|
|
2015-07-18 08:23:56 +00:00
|
|
|
You can `rm DIR/igoff` to display all URLs that are being filtered out
|
|
|
|
|
by the ignores, and `touch DIR/igoff` to turn it back off.
|
2015-07-18 06:16:46 +00:00
|
|
|
|
|
|
|
|
|
2015-07-18 10:51:17 +00:00
|
|
|
Stopping a crawl
|
|
|
|
|
---
|
|
|
|
|
You can `touch DIR/stop` or press ctrl-c, which will do the same. You will
|
|
|
|
|
have to wait for the current downloads to finish.
|
|
|
|
|
|
|
|
|
|
|
2015-07-18 12:06:00 +00:00
|
|
|
Advanced `gs-server` options
|
2015-07-18 06:16:46 +00:00
|
|
|
---
|
2015-07-18 12:06:00 +00:00
|
|
|
These environmental variables control what `gs-server` listens on:
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-07-18 06:21:03 +00:00
|
|
|
* `GRAB_SITE_HTTP_INTERFACE` (default 0.0.0.0)
|
|
|
|
|
* `GRAB_SITE_HTTP_PORT` (default 29000)
|
|
|
|
|
* `GRAB_SITE_WS_INTERFACE` (default 0.0.0.0)
|
|
|
|
|
* `GRAB_SITE_WS_PORT` (default 29001)
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-07-18 09:54:07 +00:00
|
|
|
`GRAB_SITE_WS_PORT` should be 1 port higher than `GRAB_SITE_HTTP_PORT`,
|
2015-07-20 08:50:47 +00:00
|
|
|
or else you will have to add `?host=WS_HOST:WS_PORT` to your dashboard URL.
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-07-18 06:22:47 +00:00
|
|
|
These environmental variables control which server each `grab-site` process connects to:
|
2015-07-18 06:16:46 +00:00
|
|
|
|
2015-07-18 06:21:03 +00:00
|
|
|
* `GRAB_SITE_WS_HOST` (default 127.0.0.1)
|
|
|
|
|
* `GRAB_SITE_WS_PORT` (default 29001)
|
2015-07-19 20:15:23 +00:00
|
|
|
|
|
|
|
|
|
2015-07-20 09:47:22 +00:00
|
|
|
Viewing the content in your WARC archives
|
|
|
|
|
---
|
|
|
|
|
You can use [ikreymer/webarchiveplayer](https://github.com/ikreymer/webarchiveplayer)
|
|
|
|
|
to view the content inside your WARC archives. It requires Python 2, so install it with
|
|
|
|
|
`pip` instead of `pip3`:
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
sudo apt-get install --no-install-recommends git build-essential python-dev python-pip
|
|
|
|
|
pip install --user git+https://github.com/ikreymer/webarchiveplayer
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
And use it with:
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
~/.local/bin/webarchiveplayer <path to WARC>
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
then point your browser to http://127.0.0.1:8090/
|
|
|
|
|
|
|
|
|
|
|
2015-07-27 07:59:57 +00:00
|
|
|
Thanks
|
|
|
|
|
---
|
|
|
|
|
grab-site is made possible only because of [wpull](https://github.com/chfoo/wpull),
|
|
|
|
|
written by [Christopher Foo](https://github.com/chfoo) who spent a year
|
|
|
|
|
making something much better than wget. ArchiveTeam's most pressing
|
|
|
|
|
issue with wget at the time was that it kept the entire URL queue in memory
|
|
|
|
|
instead of on disk. wpull has many other advantages over wget, including
|
|
|
|
|
better link extraction and Python hooks.
|
|
|
|
|
|
2015-07-27 08:06:33 +00:00
|
|
|
Thanks to [David Yip](https://github.com/yipdw), whose original ArchiveBot
|
|
|
|
|
dashboard inspired the newer dashboard used in grab-site.
|
2015-07-27 07:59:57 +00:00
|
|
|
|
|
|
|
|
|
2015-07-19 20:15:23 +00:00
|
|
|
Help
|
|
|
|
|
---
|
2015-07-20 09:53:13 +00:00
|
|
|
grab-site bugs, discussion, ideas are welcome in [grab-site/issues](https://github.com/ludios/grab-site/issues).
|
2015-07-27 08:52:48 +00:00
|
|
|
If you are affected by an existing issue, please +1 it.
|
2015-07-19 20:15:23 +00:00
|
|
|
|
2015-07-20 07:50:49 +00:00
|
|
|
If a problem happens when running just `~/.local/bin/wpull -r URL` (no grab-site),
|
|
|
|
|
you may want to report it to [wpull/issues](https://github.com/chfoo/wpull/issues) instead.
|
2015-07-27 07:59:57 +00:00
|
|
|
|
|
|
|
|
|
|
|
|
|
P.S.
|
|
|
|
|
---
|
|
|
|
|
If you like grab-site, please star it on GitHub,
|
|
|
|
|
[heart it on alternativeTo](http://alternativeto.net/software/grab-site/),
|
|
|
|
|
or tweet about it.
|