Spanish scriptorium? (Madrid, Biblioteca de San Lorenzo de El Escorial, 14th century). Credit: https://medievalfragments.wordpress.com/2013/11/05/where-are-the-scriptoria/ |
||
|---|---|---|
| images | ||
| libgrabsite | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| grab-site | ||
| gs-server | ||
| patched-wpull | ||
| setup.py | ||
README.md
grab-site
grab-site is an easy preconfigured web crawler designed for backing up websites. Give grab-site a URL and it will recursively crawl the site and write WARC files.
grab-site uses wpull for crawling. The wpull options are preconfigured based on Archive Team's experience with ArchiveBot.
grab-site gives you
-
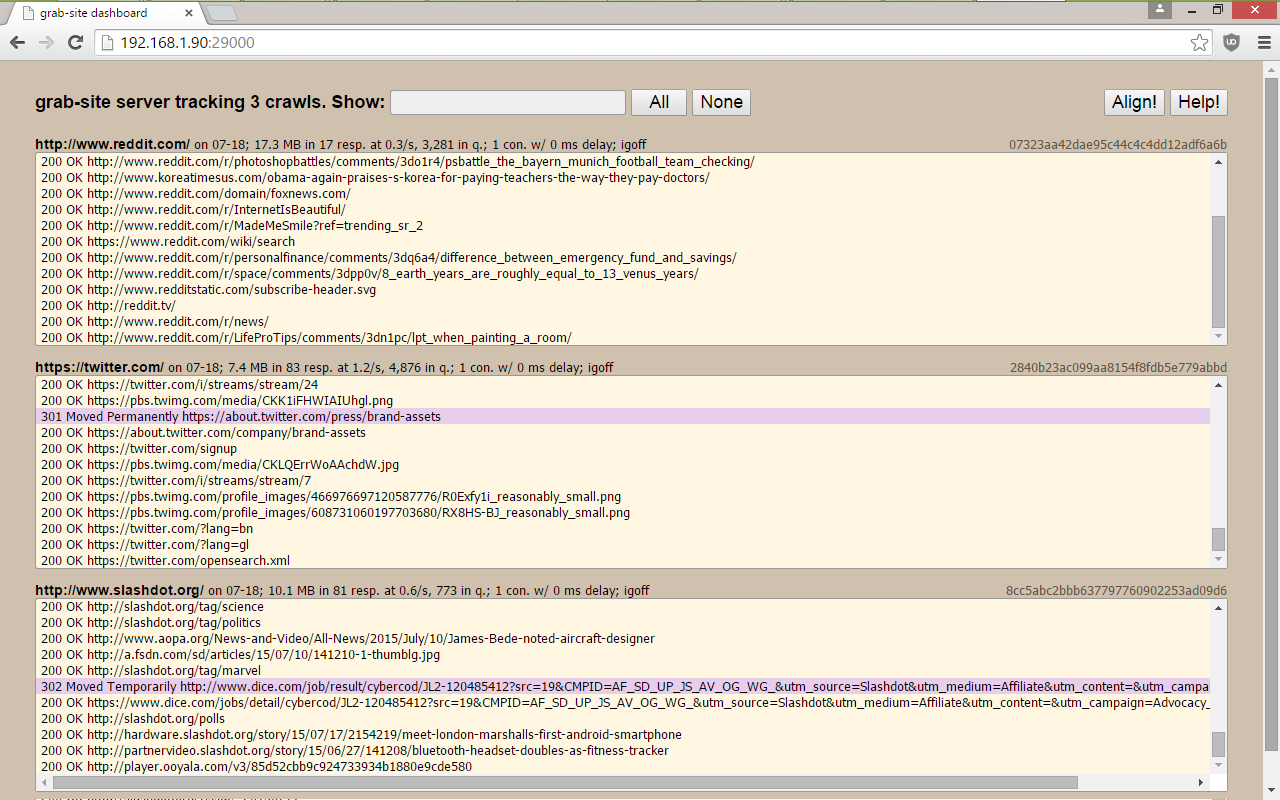
a dashboard with all of your crawls, showing which URLs are being grabbed, how many URLs are left in the queue, and more.
-
the ability to add ignore patterns when the crawl is already running. This allows you to skip the crawling of junk URLs that would otherwise prevent your crawl from ever finishing. See below.
-
an extensively tested default ignore set ("global") as well as additional (optional) ignore sets for blogs, forums, etc.
-
duplicate page detection: links are not followed on pages whose content duplicates an already-seen page.
Installation
On Ubuntu 14.04.1 or newer:
sudo apt-get install --no-install-recommends git build-essential python3-dev python3-pip
pip3 install --user git+https://github.com/ludios/grab-site
Usage
First, start the dashboard with:
~/.local/bin/gs-server
and point your browser to http://127.0.0.1:29000/
Then, start as many crawls as you want with:
~/.local/bin/grab-site URL
~/.local/bin/grab-site URL --igsets=blogs,forums
~/.local/bin/grab-site URL --igsets=blogs,forums --no-offsite-links
Do this inside tmux unless they're very short crawls.
Note: URL must come before the options.
Note: --igsets= means "ignore sets" and must have the =.
forums and blogs are some frequently-used ignore sets.
See the full list of available ignore sets.
Just as with ArchiveBot, the global ignore set is implied and enabled.
grab-site always grabs page requisites (e.g. inline images and stylesheets), even if
they are on other domains. By default, grab-site also grabs linked pages to a depth
of 1 on other domains. To turn off this behavior, use --no-offsite-links.
Using --no-offsite-links may prevent all kinds of useful images, video, audio, downloads,
etc from being grabbed, because these are often hosted on a CDN or subdomain, and
thus would otherwise not be included in the recursive crawl.
Changing ignores during the crawl
While the crawl is running, you can edit DIR/ignores and DIR/igsets; the
changes will be applied as soon as the next URL is grabbed.
DIR/igsets is a comma-separated list of ignore sets to use.
DIR/ignores is a newline-separated list of Python 3 regular expressions
to use in addition to the ignore sets.
You can rm DIR/igoff to display all URLs that are being filtered out
by the ignores, and touch DIR/igoff to turn it back off.
Stopping a crawl
You can touch DIR/stop or press ctrl-c, which will do the same. You will
have to wait for the current downloads to finish.
Advanced gs-server options
These environmental variables control what gs-server listens on:
GRAB_SITE_HTTP_INTERFACE(default 0.0.0.0)GRAB_SITE_HTTP_PORT(default 29000)GRAB_SITE_WS_INTERFACE(default 0.0.0.0)GRAB_SITE_WS_PORT(default 29001)
GRAB_SITE_WS_PORT should be 1 port higher than GRAB_SITE_HTTP_PORT,
or else you will have to add ?host=IP:PORT to your dashboard URL.
These environmental variables control which server each grab-site process connects to:
GRAB_SITE_WS_HOST(default 127.0.0.1)GRAB_SITE_WS_PORT(default 29001)
Help
Bugs, discussion, ideas are welcome in grab-site/issues.
If a problem happens when running just ~/.local/bin/wpull -r URL (no grab-site), you may want to report it to wpull/issues instead.