grab-site
grab-site is an easy preconfigured web crawler designed for backing up websites. Give grab-site a URL and it will recursively crawl the site and write WARC files. Internally, grab-site uses wpull for crawling.
grab-site gives you
-
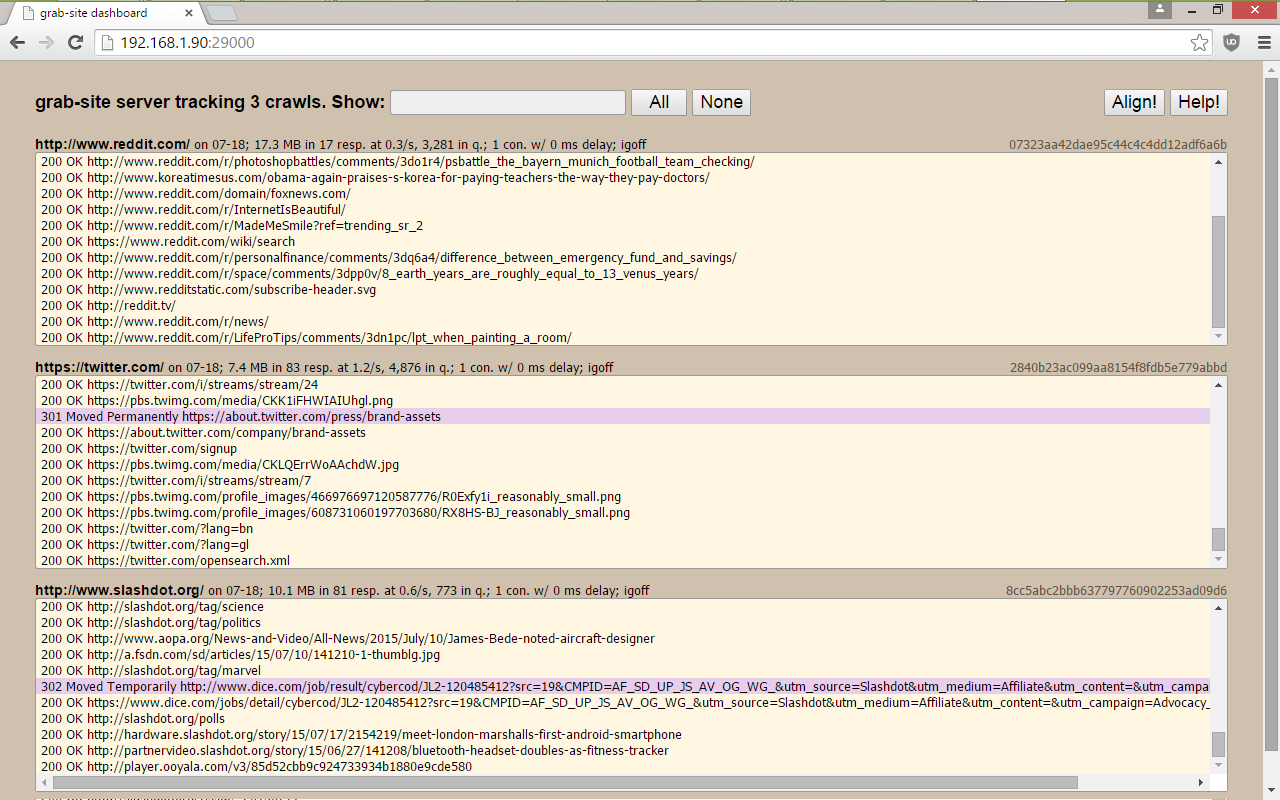
a dashboard with all of your crawls, showing which URLs are being grabbed, how many URLs are left in the queue, and more.
-
the ability to add ignore patterns when the crawl is already running. This allows you to skip the crawling of junk URLs that would otherwise prevent your crawl from ever finishing. See below.
-
an extensively tested default ignore set (global) as well as additional (optional) ignore sets for blogs, forums, etc.
-
duplicate page detection: links are not followed on pages whose content duplicates an already-seen page.
The URL queue is kept on disk instead of in memory. If you're really lucky, grab-site will manage to crawl a site with ~10M pages.
Install on Ubuntu
On Ubuntu 14.04.1 or newer:
sudo apt-get install --no-install-recommends git build-essential python3-dev python3-pip
pip3 install --user git+https://github.com/ludios/grab-site
To avoid having to type out ~/.local/bin/ below, add this to your
~/.bashrc or ~/.zshrc:
PATH="$PATH:$HOME/.local/bin"
Install on OS X
On OS X 10.10:
-
If xcode is not already installed, type
gccin Terminal; you will be prompted to install the command-line developer tools. Click 'Install'. -
If Python 3 is not already installed, install Python 3.4.3 using the installer from https://www.python.org/downloads/release/python-343/
-
pip3 install --user git+https://github.com/ludios/grab-site
Important usage note: Use ~/Library/Python/3.4/bin/ instead of
~/.local/bin/ for all instructions below!
To avoid having to type out ~/Library/Python/3.4/bin/ below,
add this to your ~/.bash_profile (which may not exist yet):
PATH="$PATH:$HOME/Library/Python/3.4/bin"
Usage
First, start the dashboard with:
~/.local/bin/gs-server
and point your browser to http://127.0.0.1:29000/
Then, start as many crawls as you want with:
~/.local/bin/grab-site URL
Do this inside tmux unless they're very short crawls.
grab-site outputs WARCs, logs, and control files to a new subdirectory in the
directory from which you launched grab-site, referred to here as "DIR".
(Use ls -lrt to find it.)
Options
Options can come before or after the URL.
-
--1: grab justURLand its page requisites, without recursing. -
--concurrency=N: Use N connections to fetch in parallel (default: 2). Can be changed during the crawl by editing theDIR/concurrencyfile. -
--igsets=blogs,forums: use ignore setsblogsandforums.Ignore sets are used to avoid requesting junk URLs using a pre-made set of regular expressions.
forumsandblogsare some frequently-used ignore sets. See the full list of available ignore sets.The global ignore set is implied and always enabled.
The ignore sets can be changed during the crawl by editing the
DIR/igsetsfile. -
--no-offsite-links: avoid following links to a depth of 1 on other domains.grab-site always grabs page requisites (e.g. inline images and stylesheets), even if they are on other domains. By default, grab-site also grabs linked pages to a depth of 1 on other domains. To turn off this behavior, use
--no-offsite-links.Using
--no-offsite-linksmay prevent all kinds of useful images, video, audio, downloads, etc from being grabbed, because these are often hosted on a CDN or subdomain, and thus would otherwise not be included in the recursive crawl. -
--delay=N: Wait N milliseconds (default: 0) between requests on each concurrent fetcher. Can be a range like X-Y to use a random delay between X and Y. Can be changed during the crawl by editing theDIR/delayfile. -
--level=N: recurseNlevels instead ofinflevels. -
--page-requisites-level=N: recurse page requisitesNlevels instead of5levels. -
--no-sitemaps: don't queue URLs fromsitemap.xmlat the root of the site. -
--help: print help text.
Changing ignores during the crawl
While the crawl is running, you can edit DIR/ignores and DIR/igsets; the
changes will be applied within a few seconds.
DIR/igsets is a comma-separated list of ignore sets to use.
DIR/ignores is a newline-separated list of Python 3 regular expressions
to use in addition to the ignore sets.
You can rm DIR/igoff to display all URLs that are being filtered out
by the ignores, and touch DIR/igoff to turn it back off.
Inspecting the URL queue
Inspecting the URL queue is usually not necessary, but may be helpful for adding ignores before grab-site crawls a large number of junk URLs.
To dump the queue, run:
~/.local/bin/gs-dump-urls DIR/wpull.db todo
Four other statuses can be used besides todo:
done, error, in_progress, and skipped.
You may want to pipe the output to sort and less:
~/.local/bin/gs-dump-urls DIR/wpull.db todo | sort | less -S
Stopping a crawl
You can touch DIR/stop or press ctrl-c, which will do the same. You will
have to wait for the current downloads to finish.
Advanced gs-server options
These environmental variables control what gs-server listens on:
GRAB_SITE_HTTP_INTERFACE(default 0.0.0.0)GRAB_SITE_HTTP_PORT(default 29000)GRAB_SITE_WS_INTERFACE(default 0.0.0.0)GRAB_SITE_WS_PORT(default 29001)
GRAB_SITE_WS_PORT should be 1 port higher than GRAB_SITE_HTTP_PORT,
or else you will have to add ?host=WS_HOST:WS_PORT to your dashboard URL.
These environmental variables control which server each grab-site process connects to:
GRAB_SITE_WS_HOST(default 127.0.0.1)GRAB_SITE_WS_PORT(default 29001)
Viewing the content in your WARC archives
You can use ikreymer/webarchiveplayer
to view the content inside your WARC archives. It requires Python 2, so install it with
pip instead of pip3:
sudo apt-get install --no-install-recommends git build-essential python-dev python-pip
pip install --user git+https://github.com/ikreymer/webarchiveplayer
And use it with:
~/.local/bin/webarchiveplayer <path to WARC>
then point your browser to http://127.0.0.1:8090/
Thanks
grab-site is made possible only because of wpull, written by Christopher Foo who spent a year making something much better than wget. ArchiveTeam's most pressing issue with wget at the time was that it kept the entire URL queue in memory instead of on disk. wpull has many other advantages over wget, including better link extraction and Python hooks.
Thanks to David Yip, who created ArchiveBot. The wpull hooks in ArchiveBot served as the basis for grab-site. The original ArchiveBot dashboard inspired the newer dashboard now used in both projects.
Help
grab-site bugs, discussion, ideas are welcome in grab-site/issues. If you are affected by an existing issue, please +1 it.
If a problem happens when running just ~/.local/bin/wpull -r URL (no grab-site),
you may want to report it to wpull/issues instead.